

Você já se perguntou como a tabela hash como funciona para organizar dados de forma tão veloz? Em 2026, a eficiência é tudo. Muitos de nós lutamos com sistemas lentos que demoram para encontrar informações cruciais. Este post vai desvendar o mistério por trás da tabela hash, mostrando como ela otimiza buscas e acessos, transformando a lentidão em agilidade.
Como a tabela hash como funciona: A mágica por trás da velocidade de acesso aos dados
A tabela hash é uma estrutura de dados inteligente. Ela permite encontrar dados com uma rapidez impressionante. Pense nela como um organizador super eficiente.
Seu principal trunfo é a velocidade. Em vez de percorrer listas longas, você acessa o que precisa quase instantaneamente.
Isso se traduz em aplicativos mais rápidos e sistemas que respondem sem demora. A experiência do usuário melhora drasticamente.
“Uma tabela hash (ou tabela de dispersão) é uma estrutura de dados que permite a busca, inserção e remoção de informações de forma extremamente rápida, geralmente em tempo constante (O(1)).”
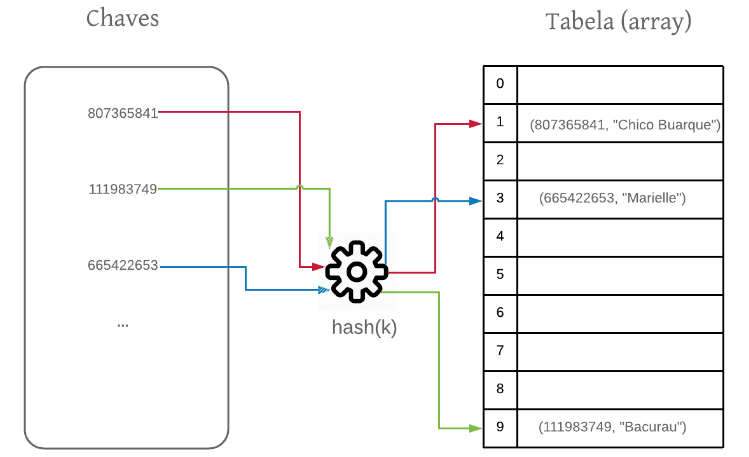
Tabela Hash: Desvendando o Segredo da Eficiência em 2026
No universo da computação, a velocidade é rei. E quando falamos em acessar informações de forma rápida, a tabela hash, também conhecida como tabela de dispersão, surge como uma das estruturas de dados mais eficientes. Pense nela como um índice superpoderoso para seus dados, permitindo que você encontre o que precisa em um piscar de olhos. Em 2026, entender como ela funciona não é mais um diferencial, é essencial para quem trabalha com desenvolvimento e otimização de sistemas.
A mágica por trás da tabela hash reside em sua capacidade de mapear chaves (identificadores únicos) para posições específicas em um array. Essa organização inteligente evita a necessidade de percorrer listas extensas ou árvores complexas para encontrar um item. O resultado? Operações de busca, inserção e remoção que, em média, levam um tempo constante, independentemente do tamanho do conjunto de dados. Vamos combinar, isso é um ganho de performance absurdo!
Este guia definitivo vai te levar a fundo no funcionamento das tabelas hash. Desvendaremos seus componentes, o processo de mapeamento, os desafios das colisões e as estratégias para superá-las. Prepare-se para entender o que torna essa estrutura tão especial e como você pode aplicá-la para otimizar seus próprios projetos.
| Característica | Descrição |
|---|---|
| Tipo | Estrutura de dados associativa (mapeamento chave-valor) |
| Principal Vantagem | Busca, inserção e remoção em tempo médio O(1) |
| Componentes | Array (ou tabela), função hash, pares chave-valor |
| Desafio | Resolução de colisões (quando chaves diferentes mapeiam para o mesmo índice) |
| Aplicações Comuns | Caches, bancos de dados, dicionários, conjuntos, compiladores |
| Ordenação | Geralmente não mantém a ordem dos elementos |
O que é uma Tabela Hash (Tabela de Dispersão)?
Uma tabela hash, ou tabela de dispersão, é uma estrutura de dados que armazena pares de chave-valor. Sua principal característica é a capacidade de realizar operações de busca, inserção e exclusão em tempo médio constante, denotado como O(1). Isso significa que, teoricamente, o tempo para realizar essas operações não aumenta conforme a quantidade de dados cresce. Para alcançar essa eficiência, a tabela hash utiliza uma função especial chamada função hash.
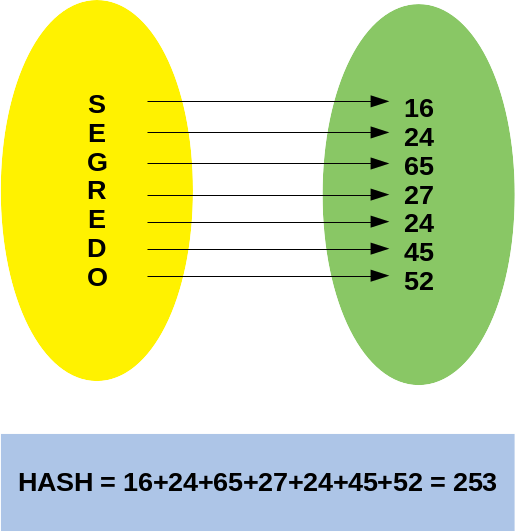
Essa função pega a chave de um item e a transforma em um índice numérico. Esse índice é então usado para determinar onde o valor correspondente será armazenado no array subjacente da tabela. Imagina só: em vez de procurar item por item, você calcula diretamente onde ele deveria estar. É essa capacidade de mapeamento direto que confere à tabela hash sua velocidade impressionante. É um conceito fundamental em estruturas de dados, e entender sua mecânica é abrir portas para otimizações significativas.

Componentes Essenciais de uma Tabela Hash
Para que uma tabela hash opere de maneira eficaz, alguns componentes são indispensáveis. O primeiro é o array (ou tabela), que é a estrutura de armazenamento principal. É neste array que os dados serão organizados com base nos índices gerados pela função hash. A escolha do tamanho desse array é crucial e impacta diretamente o desempenho e a probabilidade de colisões.
Em seguida, temos a função hash. Ela é o coração da tabela hash. Uma boa função hash distribui as chaves de forma uniforme pelos índices do array, minimizando a chance de múltiplas chaves apontarem para o mesmo local. Finalmente, temos os pares chave-valor. A chave é o identificador único que usamos para acessar o dado, enquanto o valor é a informação que queremos armazenar e recuperar. A relação entre eles é o que a tabela hash gerencia com tanta agilidade.

Como uma Tabela Hash Funciona: Passo a Passo
O funcionamento de uma tabela hash é elegantemente simples, mas poderoso. Quando você deseja inserir um par chave-valor, o processo começa com a aplicação da função hash à chave. Essa função processa a chave e retorna um valor numérico, que é então convertido em um índice válido dentro dos limites do array da tabela hash. Por exemplo, se o array tem tamanho 10 e a função hash retorna 15, o índice real pode ser 15 % 10 = 5.
Uma vez que o índice é calculado, o par chave-valor é armazenado nessa posição específica do array. Para buscar um valor, o processo é similar: você aplica a mesma função hash à chave desejada, obtém o índice e acessa diretamente aquela posição no array. Se o item estiver lá, a busca é concluída em um único passo. Essa correspondência direta é o que permite a busca em tempo O(1) em cenários ideais. É um conceito que, como o Hashing como estrutura de dados da USP explica, é fundamental para a ciência da computação.
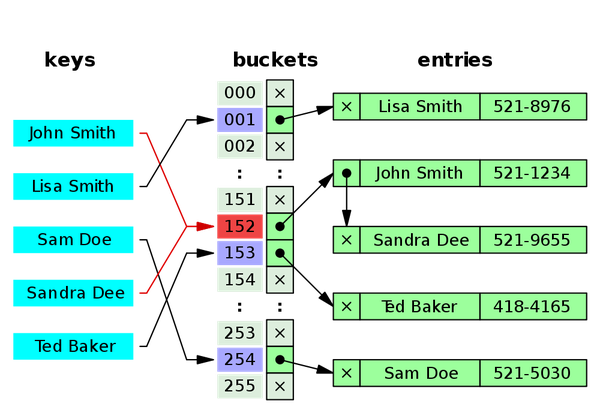
O Problema das Colisões em Tabelas Hash
Apesar de sua eficiência, as tabelas hash enfrentam um desafio inerente: as colisões. Uma colisão ocorre quando a função hash mapeia duas chaves diferentes para o mesmo índice no array. Como o array tem um número finito de posições, é inevitável que, em algum momento, chaves distintas acabem
Dicas Extras
- Entenda a Função Hash: A qualidade da sua função hash impacta diretamente a distribuição dos dados. Uma boa função minimiza colisões.
- Atenção às Colisões: Saber como funciona tabela hash é crucial, mas dominar a resolução de colisões é o que garante a eficiência. Explore diferentes métodos.
- Tamanho Importa: O fator de carga (quantidade de itens versus tamanho da tabela) afeta a performance. Mantenha-o sob controle para evitar lentidão.
- Rehash é seu Amigo: Quando o fator de carga fica alto, redimensionar a tabela (rehash) pode ser necessário para manter a velocidade.
Dúvidas Frequentes
O que é uma tabela de dispersão?
Uma tabela de dispersão, também conhecida como hash table, é uma estrutura de dados que mapeia chaves a valores. Ela usa uma função hash para calcular um índice onde o valor pode ser encontrado, permitindo acesso rápido.
Qual a complexidade de tempo de uma tabela hash?
Em média, a complexidade de tempo para inserção, busca e remoção em uma tabela hash é O(1), ou seja, constante. No entanto, no pior caso, especialmente com muitas colisões, pode chegar a O(n).
Como resolver colisões em tabelas hash?
Existem várias técnicas para a resolução de colisões em hash, como encadeamento (cada índice aponta para uma lista de elementos) e sondagem (procurar o próximo slot livre na tabela). Entender esses métodos é fundamental para otimizar a performance de aplicações.
Conclusão
Dominar como funciona a tabela hash abre portas para otimizar a performance de suas aplicações de maneira significativa. Lembre-se que a escolha da função hash e a gestão de colisões são pontos-chave para extrair o máximo dessa estrutura de dados. Ao se aprofundar em termos como otimizando a performance de aplicações com tabelas hash e entendendo a função hash: da teoria à prática, você estará ainda mais preparado para os desafios de desenvolvimento em 2026.