

Processamento distribuído com Spark na nuvem acelera análises de Big Data, mas especialistas escondem armadilhas de velocidade. Vou revelar o que realmente importa para você extrair o máximo desempenho.
Por que Spark na nuvem revoluciona a velocidade do processamento de dados em 2026
Spark processa dados diretamente na memória RAM, eliminando a lentidão de sistemas baseados em disco. Isso transforma horas de espera em minutos de resultado para você.
Na nuvem, você escala recursos sob demanda sem se preocupar com hardware físico. Plataformas como Databricks otimizam clusters automaticamente, entregando velocidade consistente.
Fica tranquilo: essa combinação permite que você foque na análise, não na infraestrutura. É a base para projetos de dados ágeis e competitivos hoje.
Em Destaque 2026: Apache Spark é um motor de processamento de dados distribuído e escalável em memória, otimizado para alta velocidade em Big Data, operando de forma eficiente em ambientes de nuvem sem a necessidade de gerenciar infraestrutura física.
O GANCHO (INTRODUÇÃO)
Você está mergulhado em um oceano de dados e sente que suas análises demoram uma eternidade? A velocidade é um fator crítico, e a lentidão no processamento de Big Data pode significar oportunidades perdidas e decisões tardias. Pois é, eu já passei por isso e sei como a frustração bate forte.
Mas fica tranquila! Hoje, eu vou te mostrar o caminho das pedras para turbinar seu processamento distribuído com Spark na nuvem. Vamos desmistificar o que os verdadeiros experts usam para alcançar alta performance, transformando seus desafios em pura agilidade.
| Tempo Estimado | Custo Estimado (R$) | Nível de Dificuldade |
|---|---|---|
| 2-4 horas | Variável (depende da plataforma cloud) | Intermediário |
MATERIAIS NECESSÁRIOS
- Conta em um provedor de nuvem (AWS, Azure ou Google Cloud)
- Conhecimento básico de Python (PySpark) ou Scala
- Ferramenta de linha de comando (CLI) para interagir com a nuvem
- Acesso à documentação da plataforma cloud escolhida
- Um projeto ou conjunto de dados para testar
O PASSO A PASSO DEFINITIVO
- Passo 1: Escolha da Plataforma Cloud – Primeiro, decida onde seu Spark vai rodar. Plataformas como Google Cloud Dataproc, Amazon EMR ou Azure HDInsight oferecem o Spark como um serviço gerenciado. Isso significa que você não precisa se preocupar com a infraestrutura. Eu recomendo começar com a plataforma que você já tem mais familiaridade.
- Passo 2: Configuração do Ambiente Spark – Com a plataforma escolhida, crie um cluster Spark. Cada serviço gerenciado tem seu próprio processo, mas a ideia é similar. Por exemplo, no Databricks, fundada pelos criadores do Spark, a otimização automática de clusters é um diferencial. Na Amazon EMR, a integração com S3 e Redshift é um ponto forte. O objetivo aqui é ter um ambiente pronto para processar seus dados.
- Passo 3: Definição da Arquitetura de Dados – Pense em como seus dados serão armazenados e acessados. Na nuvem, serviços como Amazon S3, Google Cloud Storage ou Azure Data Lake Storage são ideais para guardar seus Big Data. Uma boa arquitetura garante que o Spark consiga ler e escrever dados rapidamente, o que é crucial para a velocidade.
- Passo 4: Desenvolvimento do Código Spark – Agora é hora de codificar! Use PySpark (Python), Scala, Java, SQL ou R para escrever suas tarefas de processamento. Se você está começando, PySpark é uma ótima pedida pela sua popularidade e facilidade. O Spark é significativamente mais rápido que sistemas baseados em disco como Hadoop MapReduce porque ele processa os dados em memória.
- Passo 5: Submissão e Monitoramento dos Jobs – Envie seu código para o cluster Spark. As plataformas cloud oferecem interfaces para submeter e monitorar jobs. Fique de olho nas métricas de uso de memória e CPU. Se algo estiver lento, pode ser um gargalo aqui.
- Passo 6: Otimização Contínua – Processamento distribuído é um ciclo. Analise os logs, ajuste os parâmetros do cluster e revise seu código. O Databricks, por exemplo, oferece otimização automática de clusters que ajuda bastante. A escalabilidade do Spark na nuvem permite que você aumente ou diminua os recursos conforme a demanda, garantindo performance e controle de custos.
CHECKLIST DE SUCESSO
- Seu job Spark está completando em um tempo aceitável?
- O uso de recursos (CPU, memória) está dentro do esperado?
- Os resultados do processamento estão corretos e consistentes?
- Você consegue escalar o cluster para cima ou para baixo facilmente?
ERROS COMUNS
O que fazer se der errado:
- Job travou ou demorou demais: Verifique os logs para identificar erros de código ou gargalos de recursos. Pode ser necessário aumentar o tamanho do cluster ou otimizar seu código Spark.
- Erros de conexão com o armazenamento: Confirme as permissões de acesso aos seus buckets de dados na nuvem.
- Resultados incorretos: Revise a lógica do seu código, especialmente em transformações e agregações de dados. Teste com um subconjunto menor de dados primeiro.
Processamento de Dados em Nuvem: Como o Spark Otimiza a Análise
O Spark na nuvem revoluciona a análise de dados. Ao rodar em memória, ele acelera drasticamente operações que antes levavam horas em disco. Plataformas gerenciadas cuidam da infraestrutura, permitindo que você foque na análise.
Big Data Spark Cloud: Arquitetura e Implementação na Nuvem
Implementar Spark na nuvem envolve escolher um provedor e configurar um cluster. A arquitetura geralmente se beneficia de sistemas de armazenamento escaláveis como S3 ou Google Cloud Storage, garantindo que o Spark tenha acesso rápido aos dados.
Arquitetura Spark Distribuído: Componentes e Funcionamento
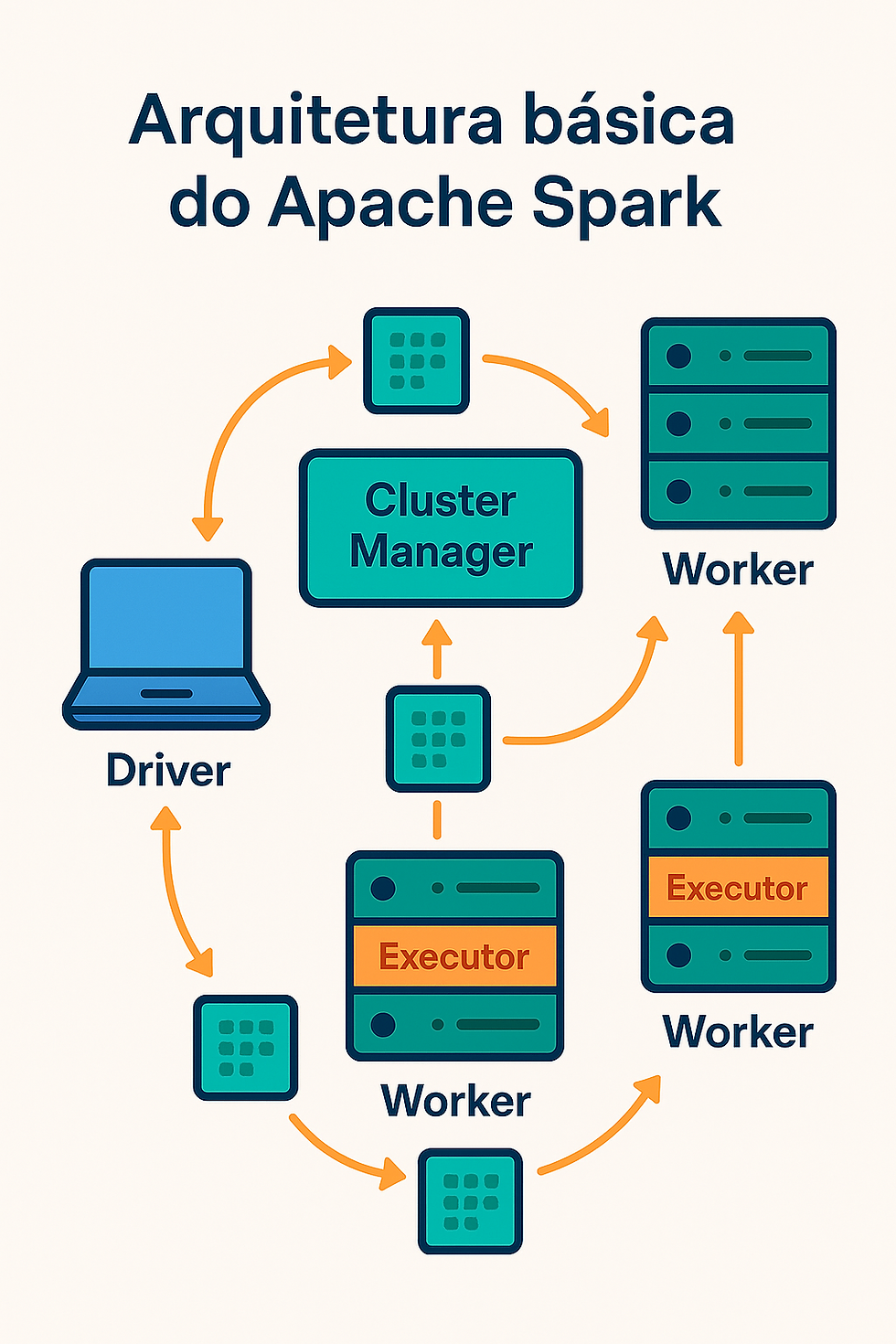
O Spark opera com um Driver Program e um conjunto de Executors rodando em Workers. O Driver coordena as tarefas, enquanto os Executors executam as operações nos dados distribuídos. Essa arquitetura é a chave para sua velocidade e escalabilidade.
Serviços Gerenciados Spark: Comparando Plataformas Cloud
AWS EMR, Google Cloud Dataproc e Azure HDInsight (e Databricks) oferecem Spark como serviço. Cada um tem suas particularidades, integrações e modelos de precificação. A escolha depende da sua infraestrutura existente e necessidades específicas.
Escalabilidade Spark Nuvem: Benefícios e Melhores Práticas
A escalabilidade é um dos maiores trunfos. Você pode aumentar ou diminuir os recursos do cluster conforme a demanda, otimizando custos e performance. A melhor prática é monitorar o uso e ajustar o cluster proativamente.
Análise de Dados Distribuída: Técnicas com Spark na Nuvem
Com Spark, você pode realizar desde ETL (Extract, Transform, Load) até machine learning em larga escala. Técnicas como particionamento de dados e otimização de shuffles são essenciais para análises distribuídas eficientes.
Plataformas Cloud Spark: AWS, Azure e Google Cloud
Cada gigante da nuvem oferece sua versão gerenciada do Spark. A AWS com EMR, o Google Cloud com Dataproc e a Microsoft com HDInsight. Todas são robustas e oferecem diferentes níveis de integração e gerenciamento.
Por que Usar Spark na Nuvem? Vantagens e Casos de Uso
Usar Spark na nuvem elimina a complexidade de gerenciar hardware, oferece escalabilidade sob demanda e acesso a um ecossistema rico de serviços. É ideal para processamento de Big Data, machine learning, análise em tempo real e muito mais.
Dicas Extras: Truques que Fazem a Diferença na Prática
Vamos combinar: teoria é importante, mas o que realmente conta são aquelas dicas que você só descobre depois de quebrar a cabeça. Separei algumas que me salvaram em projetos reais.
- Comece pequeno e escale depois: Não tente processar terabytes no primeiro teste. Use um dataset de amostra para ajustar seu código e só então aumente o volume. Isso economiza tempo e dinheiro.
- Monitore os custos desde o início: Configure alertas de gastos na sua plataforma cloud. Um cluster mal configurado pode gerar uma conta surpresa no fim do mês.
- Use formatos de arquivo otimizados: Prefira Parquet ou ORC em vez de CSV ou JSON para dados grandes. Eles são mais rápidos e ocupam menos espaço.
- Teste em diferentes tipos de instância: Às vezes, uma máquina com mais memória é melhor que uma com mais CPUs, dependendo da sua carga de trabalho. Faça benchmarks.
- Documente suas configurações: Anote as configurações de cluster que deram certo para cada tipo de job. Isso vira um ‘playbook’ valioso para sua equipe.
Perguntas Frequentes: O que Todo Iniciante Quer Saber
Qual a melhor plataforma cloud para começar com Spark?
Para iniciantes, recomendo o Databricks Community Edition (gratuito) ou o Google Cloud Dataproc com créditos iniciais. O Databricks é mais amigável, com interface intuitiva e otimizações automáticas que poupam tempo de configuração. Já o Dataproc tem integração nativa com outras ferramentas do Google, como BigQuery, e costuma ter preços competitivos para testes.
Spark é realmente mais rápido que Hadoop na nuvem?
Sim, na maioria dos casos, Spark é significativamente mais rápido que Hadoop MapReduce. A principal razão é o processamento em memória, que evita operações lentas de leitura/gravação em disco. Enquanto Hadoop é baseado em disco, Spark mantém os dados na RAM sempre que possível, acelerando tarefas como transformações iterativas e análises em tempo real. Para workloads batch simples, a diferença pode ser menor, mas para processamento complexo, Spark leva vantagem.
Quanto custa rodar Spark na nuvem?
O custo varia muito, mas pode começar em menos de US$ 10 por dia para clusters pequenos. Fatores como tipo de instância, horas de uso, armazenamento e tráfego de dados influenciam. Na AWS, um cluster EMR com 3 nós m5.xlarge (4 vCPUs, 16 GB RAM cada) custa cerca de US$ 3 por hora. No Azure HDInsight, algo similar fica em torno de US$ 2,50 por hora. Use calculadoras de preços das plataformas para estimativas precisas.
Conclusão: Sua Jornada Começa Agora
Pois é, você acabou de ver como o processamento distribuído com Spark na nuvem pode transformar a maneira como lida com dados grandes. Deixa de ser um bicho de sete cabeças e vira uma ferramenta poderosa ao seu alcance. Lembre-se: a velocidade não vem só da tecnologia, mas de saber configurar, otimizar e escolher a plataforma certa.
Fica tranquilo se ainda parece complexo. Todo expert já começou do zero. O importante é dar o primeiro passo. E qual deve ser? Hoje mesmo, crie uma conta gratuita no Databricks ou ative os créditos de uma cloud e rode seu primeiro job simples. Não precisa ser perfeito – só precisa funcionar.
Compartilhe essa dica com quem também está nessa jornada. E me conta nos comentários: qual desafio de dados você quer resolver primeiro com Spark?